4月28日,云创大数据正式发文公布了云创学习工场可以为高校提供高质量免费直播授课的通知。消息一经发出,受到各高校的积极反馈。目前为止,已有56所高校通过微信小程序报名,选择了相关课程,分布在全国29个省、直辖市和自治区。
从5月25日开始,这些高校的学生将学习《大数据》课程和《大数据导论》课程,并将免费使用云创大数据开发的大数据实验平台(本科与高职两大平台,金融、电子商务、数学统计等多个版本,共有424个大数据实验)进行实战实验,可以享受到直播授课+答疑解惑+实验实战等个性化的服务和指导。
开课时间在即,请还没报名,有意向选择云创学习工场高质量免费直播授课的高校抓紧时间通过下文中小程序报名!具体课程详情和相关细节,可阅读后文!
注:《大数据》课程适合作为本科高校大数据专业必修课程、非大数据专业选修课程。《大数据导论》课程适合作为高职高专院校大数据专业必修课程、非大数据专业选修课程。各高校也可以同时选择以上两门课程!
《大数据》选课小程序码:

《大数据导论》选课小程序码:

针对目前高校面临的课程、师资、科研支撑、成果转化等瓶颈,云创专业共建结对子计划可为合作院校提供“共同制定人才培养计划、建设教材体系、高质量免费培养师资、全套专业课高质量免费在线直播教学、设计实验室建设方案、协助学生实习、协助学生高质量就业、共建教育部协同育人项目、联合科研项目申报与研究、联合发表高质量论文、联合科研成果报奖、助力科研成果转化”共12项免费服务,在教育领域反响十分强烈。
其中,高质量免费培养师资和全套专业课高质量免费在线直播教学作为重要的两项服务,受到不同层次高校的广泛好评。而全套专业课高质量免费在线直播教学采用“双师模式”——直播间老师负责授课,现场助教老师负责辅导,可以大大解决大数据和人工智能师资紧缺问题,提升教学质量。
为了帮助高校大数据专业建设快速落地,培养创新人才,云创大数据将从本学期5月25日开始,推出《大数据》和《大数据导论》免费在线直播课,欢迎各高校选修。
《大数据》适合于本科高校大数据专业必修课程和非大数据专业选修课程,《大数据导论》适合于高职高专院校大数据专业必修课程和非大数据专业选修课程。同时,为了保障高校的教学实践效果,云创大数据还将为选修以上两门课程的高校免费提供大数据实验平台(本科与高职两大平台,金融、电子商务、数学统计等多个版本,共有424个大数据实验),让高校享受直播授课+答疑解惑+实验实战等个性化的服务和指导。
云创大数据还计划从下学期9月份开始提供9门大数据和人工智能专业的专业直播课程,敬请期待!具体课程如下:
大数据(本科):《大数据》、《Python程序设计》、《云计算》
大数据(专科):《大数据导论》、《Python语言》、《云计算导论》
人工智能(本科):《人工智能导论》、《Python程序设计》、《人工智能数学基础》
人工智能(专科):《人工智能概论》、《Python语言》、《云计算导论》
如有疑问,请咨询宋倩:
联系方式:
邮箱:songqian@cstor.cn
手机:13905177044

大数据(适合于本科高校)
一、课程性质、目的与要求
课程性质:本科高校大数据专业必修课程、非大数据专业选修课程。
课程目的:通过对大数据的相关知识介绍,使学生掌握大数据的概念和原理,熟悉大数据的理论与算法,了解大数据未来发展趋势,能够利用所学知识,进行大数据应用实现和算法设计,培养学生运用大数据技术解决大数据行业应用问题。
课程要求:本课程系统介绍了大数据的理论知识和实战应用,包括大数据概念与应用、数据采集与预处理、数据挖掘算法与工具、R语言、深度学习以及大数据可视化等,并深度剖析了大数据在互联网、商业和典型行业的应用。期望学生对大数据处理技术有比较深入的理解,能够从具体问题或实例入手,利用所学的大数据知识在应用中实现数据分析和数据挖掘。
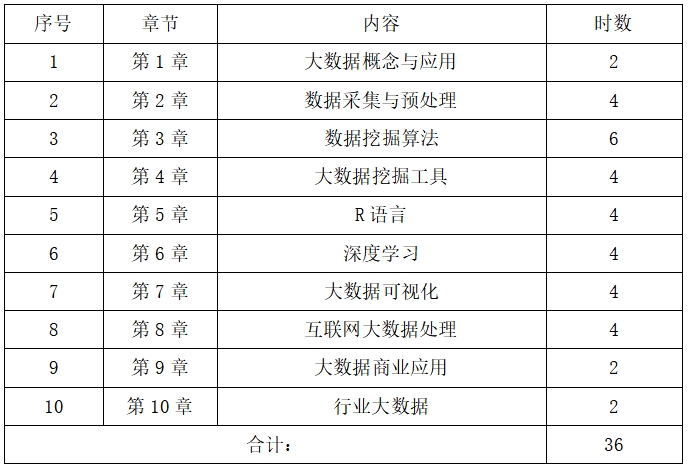
二、教学内容
总学时:36学时
第1章 大数据概念与应用 2学时
基本要求:熟悉大数据的概念与意义、大数据的来源、大数据应用场景及大数据处理方法等内容。
重点:大数据的定义、研究内容与应用。
难点:无。
第2章 数据采集与预处理 4学时
基本要求:熟悉常用的大数据采集工具,特别是Apache Kafka数据采集使用方法;熟悉数据预处理原理和方法,包括数据清洗、数据集合、数据转换;掌握数据仓库概念与ETL工具Kettle的实际应用。
重点:Apache Kafka数据采集、数据清洗、数据仓库与ETL工具。
难点:ETL工具Kettle的实际应用。
第3章 数据挖掘算法 6学时
基本要求:熟悉常用的数据挖掘算法,内容上从分类、聚类、关联规则和预测模型等数据挖掘常用分析方法出发掌握相对应的算法,并能熟练进行数据挖掘算法的综合应用。
重点:分类算法、聚类算法、关联规则、时间序列预测。
难点:数据挖掘算法的综合应用。
第4章 大数据挖掘工具 4学时
基本要求:熟练掌握机器学习系统Mahout和大数据挖掘工具Spark Mllib下的分类算法、聚类算法、协同过滤算法的使用,并对其他数据挖掘工具有所了解。
重点:Mahout安装与使用、Spark Mllib工具的使用。
难点:Mahout和Spark Mllib工具的使用。
第5章 R语言 4学时
基本要求:了解R语言的发展历程、功能和应用领域;熟悉R语言在数据挖掘中的应用;掌握R语言在分布式并行实时计算环境Spark中的应用SparkR。
重点:R语言基本功能、R语言在数据挖掘中的应用、SparkR主要机器学习算法。
难点:R语言与数据挖掘。
第6章 深度学习 4学时
基本要求:了解深度学习的发展过程和实际应用场景,并结合人脑的工作原理,理解深度学习的相关概念和工作机制,做到能够熟练使用常用的深度学习软件。
重点:人脑神经系统与深度学习、卷积神经网络、深度置信网络、循环(递归)神经网络、TensorFlow和Caffe。
难点:人工神经网络。
第7章 大数据可视化 4学时
基本要求:熟悉大数据可视化的基础知识;掌握文本可视化、网络可视化、时空数据可视化、多维数据可视化等常用的大数据可视化方法,可通过Excel、Processing、NodeXL和ECharts软件实现数据的可视化。
重点:数据可视化流程、大数据可视化方法、大数据可视化软件与工具。
难点:时空数据可视化、多维数据可视化。
第8章 互联网大数据处理 4学时
基本要求:掌握互联网信息抓取技术,能够通过互联网信息抓取、文本分词、倒排索引与网页排序这4个主要步骤实现互联网大数据处理,并能够熟练运用。
重点:Nutch爬虫、文本分词、倒排索引、网页排序。
难点:倒排索引。
第9章 大数据商业应用 2学时
基本要求:熟悉用户画像和精准营销的构建;熟悉广告推荐系统的建设;熟悉互联网金融的应用方法。
重点:用户画像构建流程、用户标签、广告推荐、互联网金融应用方向。
难点:信用评分算法、分类模型的性能评估。
第10章 行业大数据 2学时
基本要求:以地震大数据、交通大数据、环境大数据和警务大数据为例来熟悉行业大数据的应用,学会利用数据创造价值。
重点:理解数据和数据分析在业务活动中的具体表现。
难点:无。
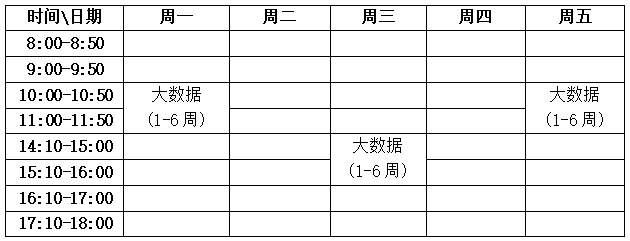
三、课程安排
通过在线直播的方式进授课。授课时间为:2020年5月25日开课
具体课程安排如下:
四、课时分配
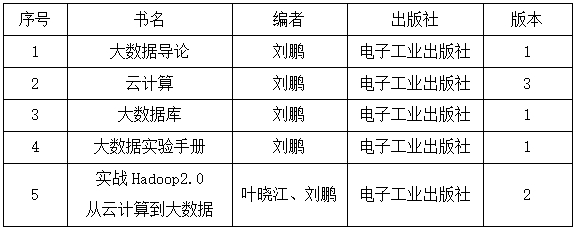
五、建议教材与教学参考书
一、课程性质、目的与要求
课程性质:高职高专院校大数据专业必修课程、非大数据专业选修课程。
课程目的:本课程力求加深学生在程序设计方法上的理解和把握,通过相关的事例让学生对各知识点先了解,再理解,最后逐步掌握。整个过程融“教、学、练”于一体,加强学生实践动手能力、独立思考问题和解决问题的能力,达到正确灵活地利用操作系统各知识点来解决相关问题的目标,并为后续专业基础课程、专业课程的学习奠定扎实的基础。
课程要求:本课程在教学过程中,根据高职培养应用型人才的特点,以典型工作任务为主线、以各种资源管理为核心,以培养能力和提高兴趣为目标,变应试为应用,重视在新形势下的新方法、新规则和新思想的传授。着重培养学生能灵活应用这些思想和方法的能力。课程教学中要遵循理论来自于实践的原则,融“教、学、练”于一体,体现“在做中学,在学中做,学以致用”,以增强知识点的实践性,激发学生的学习兴趣。在实践教学环节中则融入相关理论知识,突出理论来自于实践和指导实践的作用,使学生的知识应用根据学习的内容提升一个新的高度。
具体目标:
知识目标
大数据基本概念和应用
大数据的架构
大数据的采集和预处理
大数据的存储
大数据分析
大数据可视化
大数据的商业应用
技能目标
大数据的基本概念和应用范围
理解大数据架构的相关概念
理解大数据采集和预处理相关的概念,掌握数据采集相关技术的应用,了解大数据预处理相关技术
理解大数据存储相关概念,掌握大数据存储相关技术
了解大数据分析相关概念,了解大数据分析的相关技术
理解数据可视化的相关概念,掌握大数据可视化的相关技术
了解大数据的商业应用情况
二、教学内容
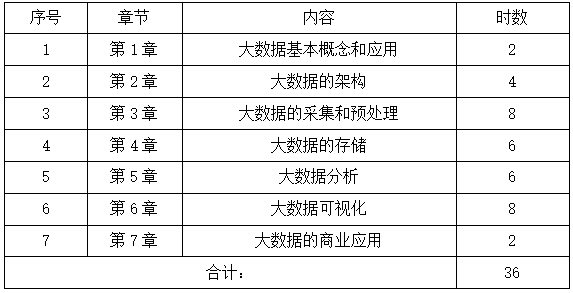
总学时:36学时
第1章 大数据基本概念和应用 2学时
基本要求:了解大数据的相关概念,了解大数据的来源、特征和意义、了解大数据的表现形态、了解大数据的各种应用场景。
重点:大数据的定义、大数据的市场应用。
难点:无。
第2章大数据的架构 4学时
基本要求:掌握大数据的分类,了解数据类型,了解大数据的解决方案、理解Hadoop的核心设计,了解Hadoop的平台搭建。
第3章 大数据的采集和预处理 8学时
基本要求:熟悉常用的大数据采集工具,特别是Apache Kafka数据采集使用方法;熟悉数据预处理原理和方法,包括数据清洗、数据集合、数据转换;掌握数据仓库概念与ETL工具的实际应用。
重点:Apache Kafka数据采集、数据清洗、数据仓库与ETL工具
重点:分类算法、聚类算法、关联规则、时间序列预测。Apache Kafka数据采集、数据清洗、数据仓库与ETL工具。ETL工具Kettle的实际应用
难点:数据挖掘算法的综合应用。
第4章 大数据的存储 6学时
基本要求:理解大数据存储相关概念、理解数据仓库的概念,了解数据仓库的组成和构建方式、掌握大数据存储相关技术的应用。
重点:云存储系统的结构模型、分布式文件系统、数据库。
第5章 大数据分析 8学时
基本要求:了解大数据分析相关概念,了解大数据分析的相关技术,通过上机项目实例进行练习。
重点:数据分析方法、数据挖掘算法。
第6章 大数据可视化 6学时
基本要求:熟悉大数据可视化的基础知识;掌握文本可视化、网络可视化、时空数据可视化、多维数据可视化等常用的大数据可视化方法,可通过Excel、Processing、NodeXL和ECharts软件实现数据的可视化。
重点:数据可视化流程、大数据可视化方法、大数据可视化软件与工具。
难点:时空数据可视化、多维数据可视化。
第7章 大数据的商业应用 2学时
基本要求:了解国外大数据应用经典案例以及以地震大数据、交通大数据、环境大数据和警务大数据为例来熟悉行业大数据的应用,学会利用数据创造价值。
重点:理解数据和数据分析在业务活动中的具体表现。
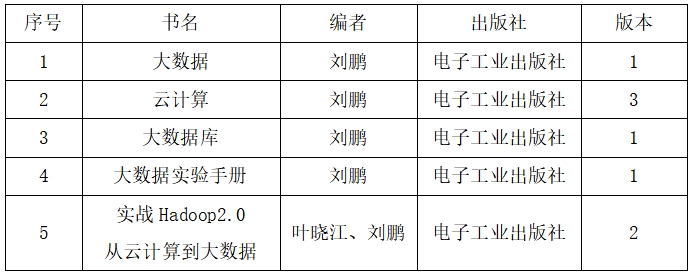
三、课程安排
通过在线直播的方式进授课。授课时间为:2020年5月25日开课
具体课程安排如下:
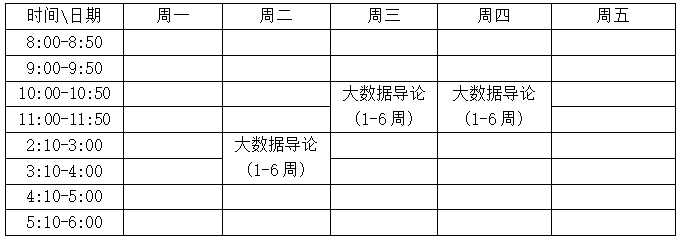
四、课时分配
五、建议教材与教学参考书